





Here at Branch, we move fast. It’s so critical to the success of our company that it is one of our core values. We are the fastest moving company I’ve worked for.
One of the keys to moving fast is allowing our development teams to iterate and test their code quickly and consistently. This means our development, deployment, and release infrastructure is key to being able to move swiftly. That’s why we invest in making sure developers are productive. I have a personal passion for empowering developers, specifically because nothing is more demoralizing than developers needlessly held back by tools or process.
Problem: Local Development Environments Are Difficult to Manage
Our core apps are written in Node.js, which call many services written primarily in Java. Our developers use Macs, but local development environments are inconsistent and our server configuration management system was only designed for Linux and wouldn’t work on the Mac. Developers self-manage the components on their Macs, including Node.js, correct versions of packages, build tools, and personal IDEs. Some developers also develop Java services, which require a different set of tools including Java, maven, another IDE and more package management tools. Setting a Mac up once isn’t hard, but local environments become a frequent and significant source of problems as tools, components, and services go out of date; causing developers to waste time troubleshooting version incompatibilities unique to each desktop. And as we develop new core services, the complexity of the dependencies can increase exponentially.
Failed Solution: Docker on the Desktop
We attempted last year to use Docker on the desktop like many organization do to create consistent and replicated environments on Macs, but multiple attempts exposed the problems of this approach.
- Docker on the desktop is difficult to manage. Exposing ports, multiple containers, linking containers are all difficult to do. Even with good tooling, diagnosing local problems is difficult and can be entangled with application issues.
- Local docker environments require developers to understand too much about Docker, Vagrant, and Docker networking.
- Running many containers is too memory and CPU intensive for many desktops.
- Managing local databases requires frequent schema maintenance and differences between each developer’s database create difficult to reproduce bugs.
- Developer are forced to either run every microservice, or understand a complex web of service dependencies in order to run only the components they need.
- Sharing work on developer laptops is inconvenient because developers run local HTTP servers without stable IP addresses or DNS entries
- Significant differences between desktop environments increase debugging difficulty.
These issues caused us to abandon local Docker environments and continue using local native development environments. But the challenges of debugging complex multi-system issues continued, especially as we continued to add more services into our evolving microservice architecture.
Successful Solution: Kubernetes-Powered Beta
We devised a system we call Beta to provide consistency and repeatability to all our development environments by leveraging the deployment, management, and scaling features of cloud services.
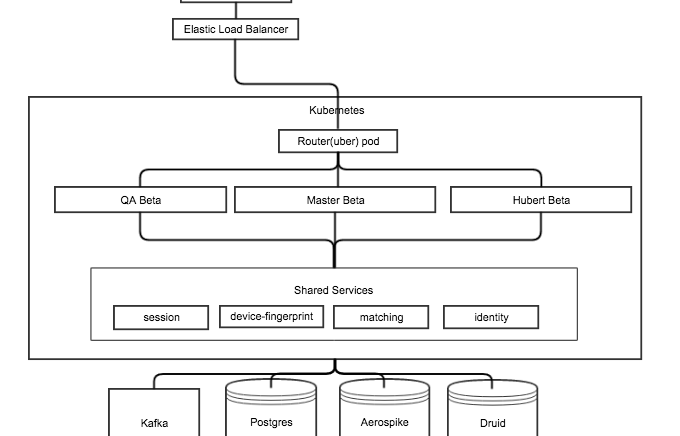
Beta gives each developer their own cloud environment in Kubernetes. It contains an individual set of core Node.js apps, but all users share backend services and databases. Using Kubernetes provides the consistency and portability of Docker containers then adds a layer of provisioning, scheduling, network management, and service discovery to provide full container life cycle management. We leave stateful services like data storage in a single shared environment outside Kubernetes so that developers have the same data to work with.
Consider the different ways different users use environments:
- Product Management: wants to see, share and test upcoming changes with real data
- Developers: value fast iteration and have personal preferences for tools
- QA: requires build consistency and repeatability
- DevOps: requires reliable deployment and rollback capabilities
Kubernetes: Why it Works
We started adopting Kubernetes earlier this year and were pleased with its power and flexibility in managing production applications. Kubernetes is a distributed management system for running Docker containers. Docker provides lightweight process isolation and a solid set of tools for building and running containers. However, Docker containers are a challenge to manage, particularly in a large dynamic system. That’s why we selected Kubernetes as a higher layer tool to control deployment and management of containers.
Inspired by the success of using Kubernetes to manage Docker containers for production, we revisited the idea using Docker for development environments, but this time using Kubernetes in AWS instead of on Docker on local machines. By running our Beta environment in Kubernetes,
we get Docker’s strengths of lightweight processes and consistency, but also the added management features to make it fast and reduce management responsibilities from developers. Then we use custom scripts to put it all together to make it a complete test environment.
How Developers Use Beta
With one command, all the following is done for our developers:
- Provision, schedule, and deploy new Beta environment
- Configure personalized node containers
- Configure containers to use shared backing services
- Startup Node.js http servers
- Expose network correctly
- Configuration of inter-service routing
- DNS setup
- SSL termination
 With Beta, updating to the most recent tested environment is a one command, two minute operation. With startup time so quick, it let us change how we think about testing.
With Beta, updating to the most recent tested environment is a one command, two minute operation. With startup time so quick, it let us change how we think about testing.
A Beta environment is created from the most recent build of our master branch, which passed its unit tests. It is already compiled and built into a working Docker image. Docker image layers are usually cached, so startup time is quick. Configuration is managed centrally, which reduces impact to developers by incorporating service changes automatically, but Beta environments are also individually configurable for situations that require it.
It is possible to use Beta as a development environment, but because developers regularly destroy their Beta environment they generally edit files on their local machines and then move them to Beta for testing. To support the most common workflow of local edit then push to Beta for testing, we created a tool to automatically rsync files from local environments into Beta. Developers can still use local development environments for editing and testing, but Beta is their fully featured personal testing environment; along with a usable development environment. Developers and QA also frequently pull different branches directly to their Beta for testing.
A typical developer workflow is:
- A developer creates their Beta which has the latest successful master build
- A developer edits files locally on their Mac
- A custom rsync tool automatically mirrors their local changes into their Beta environment
- Test in Beta. Most Node.js modules don’t need recompilation because Beta has the application pre-compiled. Some changes would require module compilation or gulp build, but only incremental recompilation
- Once a developer has tested their changes, they push a git branch from their local machine to GitHub and create a pull request.
- Once a pull request is approved, it can be merged into master which triggers a CircleCI build
- When CircleCI builds and tests master successfully a new Beta image is created
Several key features make Beta a self-service, instant, and up-to-date test environment:
- Continuous integration runs unit tests on every master commit
- Continuous integration builds complete and updates Beta image only when unit tests pass
- Containers run light enough to give developers their own cloud managed environment
- Automation makes creating Beta environments fast and easy
- Kubernetes automatically schedules and provisions docker containers
- Configuration management gives each Beta a standard configuration, but with minimal customizability
- Docker layer image caching on Kubernetes nodes lets containers start quickly
- Kubernetes service discovery enables using DNS everywhere
- Wildcard DNS covers all Betas and enables full SSL support (important because bypassing SSL validation on mobile browsers is difficult)
- Custom nginx Kubernetes Service dynamically routes each HTTP request to individual users Beta containers, known as the “uber” service because it handles all Beta traffic and routes it to the appropriate user container

Positive Results
The Beta architecture has been a significant boost to our developer productivity by improving the speed and consistency of testing. The transition has required us to re-work our build and test processes as we moved away from a static QA environment. However, the new paradigm has almost entirely removed discrepancies between dev and QA environments.
Because Beta environments are identical, we have greatly reduced “it works for me” conversations that spawn back and forth debugging sessions. These problems frequently plague local development environments because each desktop is unique. Betas are designed primarily for consistency, not flexibility. Consistency helps reduce debugging to the changes a developer has made to their own Beta. Sometimes bugs affect all Betas, but these issues are naturally easy to reproduce and debug.
Beta also makes it easier to for non-developers to dabble in the source code to test light changes, without the effort required to setup and maintain a complete local development environment.
Fast provisioning and startup time means that it’s easier to start a clean Beta environment than to troubleshoot a complex broken environment. So, developers regularly destroy and recreate their Beta environment when their environment might be inconsistent or they think a
component changed underneath them.
Other extra benefits of moving off local environments to Beta:
- Compile, build, and runtime are identical between Beta and production
- Operational equivalence of developer, QA, and production environments
- Eliminates the need to debug Mac OS, Virtualbox, and Vagrant. All environments are Ubuntu on Kubernetes
- Beta in Kubernetes helps developers understand Kubernetes and our production environment
- Ability to use DNS instead of local IPs allowing seamless access for Product / Design / QA / Eng
- Automation of Beta management processes helps organization scale much better than automating management of desktop environments
Drawbacks of moving to Beta:
- Beta requires developers to log into the VPN to do development work
- Shared service and data storage outages still affect many internal developers
- Developers don’t learn the service dependencies in the infrastructure
- Stateless containers can be rescheduled by Kubernetes unexpectedly causing confusion when they revert code on them
In particular, having all Betas share data stores is a mixed blessing. Problems are more likely to
become visible with multiple developers using the same data, but it is possible to corrupt other users data. We will likely move toward individual data stores for each Beta, but it will take planning and work to do properly.
Future Work
In the near future, each developer will be able to run the full QA integration test suite against their own Beta environment, letting developers catch their own bugs before our busy QA team sees them.
We are still improving the developer tools, but a primary goal of Beta is to make it so easy that new developers can be productive as quickly as possible. We will likely spend time continuing to improve hybrid local and Beta environments. And not all services are in Beta, but we continue to move more services there.
In the near term, we hope to give each user personal versions of any stateless services they want and use shared services for things which they don’t want to manage themselves. This will give service developers the ability to modify and break services in their own environment before pushing changes to all other internal developers. On the other hand, keeping mostly shared services minimizes utilization and reduces version drift between environments. Provisioning each user a complete environment with all services is inefficient and can create a large number of version and configuration incompatibilities. Shared services provide all developers an identical view which helps maximize visibility of moving parts and helps surface common issues faster.
In the long term, we hope to give developers fully isolated data stores for those that want it. In particular, QA could make use of clean data stores for fully repeatable test runs. This is a bigger time and infrastructure investment but one we believe worth making.
All together, Beta has greatly improved the speed and productivity of developers. The changes are still in progress, but Beta has proven to be a solid base which we can build on to let us deliver more code faster, with higher quality, and less frustration.